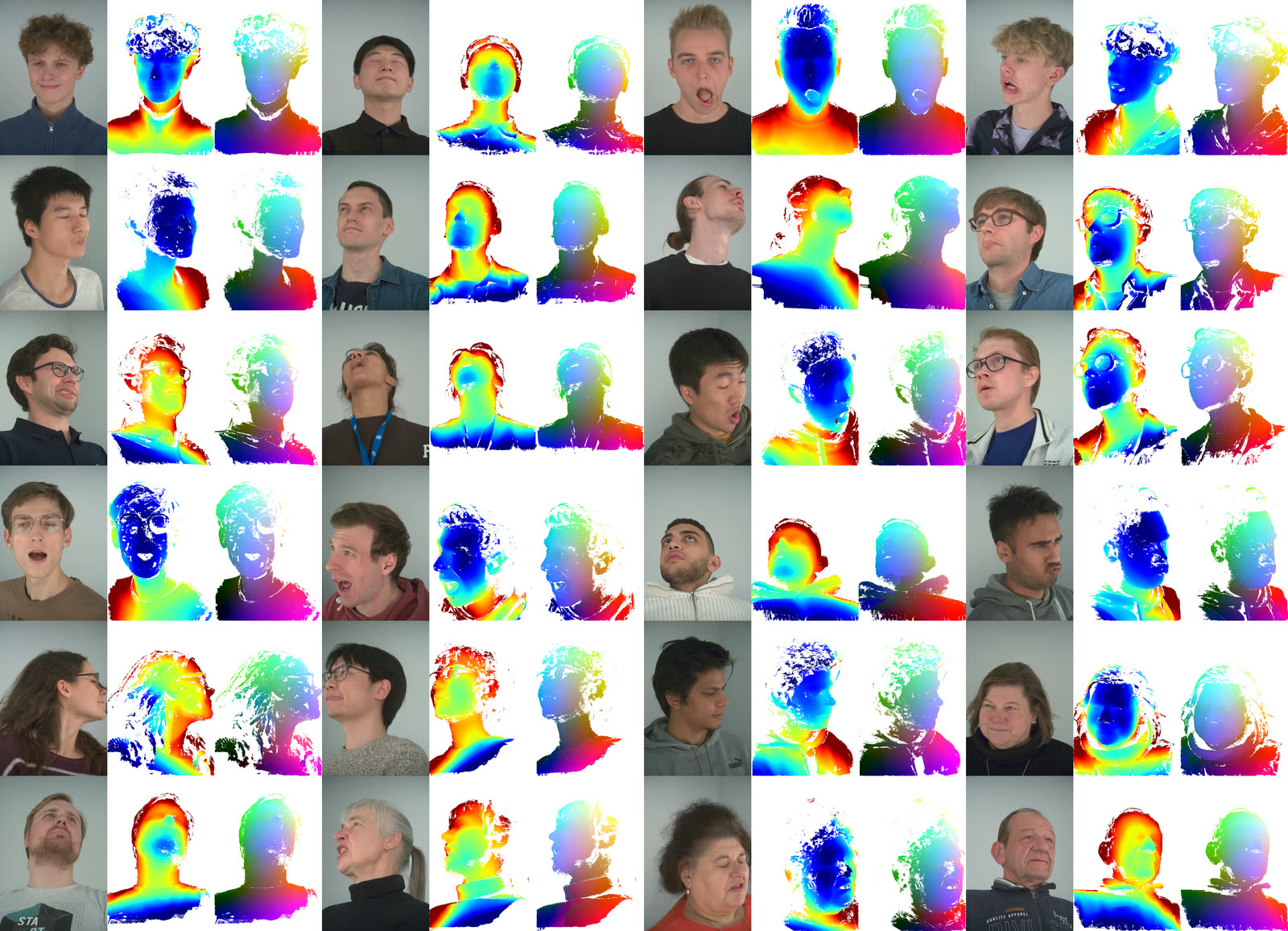
FaceAnything is a single feed-forward model that reconstructs a moving face in 3D from any image sequence. Phone video works. You get depth maps, surface normals, orbitable point clouds, and dense point tracks that stay consistent across every frame, all from one pass. No markers, no multi-camera rig, no depth sensor.
It comes out of Matthias Nießner's lab at TUM (he co-founded Synthesia) and is accepted at ECCV 2026. The code is open source and there's a free browser demo:
- Try it now: Hugging Face Space (free, runs on ZeroGPU, nothing to install)
- GitHub repo for running it on your own hardware
- Project page with the paper and full results
Why this one is different
Dense face tracking and 3D reconstruction have always been two separate problems. You track points across frames with one system, reconstruct geometry with another, and hope they agree. FaceAnything collapses them into one.
The trick is canonical facial point prediction. The model assigns every pixel a normalized coordinate in a shared canonical face space. The tip of your nose gets the same coordinate in frame 1 and frame 400, no matter how your head moves. Once every pixel knows where it lives on the canonical face, tracking is just looking up which pixels share a coordinate, and reconstruction is the same problem the model already solved.
The numbers back it up: roughly 3x lower correspondence error than prior dynamic reconstruction methods, a 16% improvement in depth accuracy, and faster inference. The backbone is Depth Anything 3 (giant), fine-tuned on multi-view face captures with FLAME-based tracking supervision.
Training data, from left to right in each triplet: RGB input, depth map, canonical coordinate map.
Try it in 2 minutes (no GPU needed)
The Hugging Face Space runs the full model on free ZeroGPU hardware:
- Upload a short video or up to 40 images. Only the first 40 frames of a video get used.
- Pick a mode. Joint processes all frames together for better 3D consistency. One-by-one handles frames independently, gives more surface detail, and uses less memory.
- Run it. You get back depth and normal videos, a 2D track overlay, and a 3D point cloud you can orbit and scrub frame by frame, plus downloadable .ply files.
Each run is capped at 120 seconds of GPU time. If it times out, drop to 10-20 frames, lower the processing resolution, or switch to one-by-one mode. Signing in to Hugging Face also gets you a bigger daily ZeroGPU quota than anonymous use.
Run it locally
This is where the requirements get real: you need a CUDA GPU. No Mac, no CPU fallback. Tested config is Python 3.11 with PyTorch 2.9 on CUDA 12.8.
conda create -n faceanything python=3.11 -y
conda activate faceanything
pip install torch==2.9.0 torchvision==0.24.0 --index-url https://download.pytorch.org/whl/cu128
pip install -r requirements.txt
pip install -e .Then grab the checkpoint. It's ~15GB, so start the download and go make coffee:
huggingface-cli download UmutKocasari/FaceAnything checkpoint.pt --local-dir checkpointsInference is one command. It takes images, a folder, or a video file:
python run_inference.py --input your_video.mp4 --output results/A full run writes per-modality videos (point cloud, tracks, canonical coordinates, depth, normals), a "grand tour" orbit that morphs through all of them, per-frame .ply point clouds, and camera intrinsics/extrinsics for every frame. Useful flags: --process-res (default 504), --process-mode for joint vs one-by-one, and --max-frames to cap the sequence.
Honest limitations
The license is CC-BY-NC-4.0, non-commercial. Research and personal projects are fine. Shipping it in a paid product or client work is not, at least without talking to the authors.
The CUDA requirement is hard. There's no MPS or CPU path, so Mac users are limited to the hosted demo. And the 15GB checkpoint means you want a card with serious VRAM, not a laptop GPU.
It's also faces only. The canonical space is a face template, so pointing it at hands, bodies, or general scenes won't work. For general geometry, the Depth Anything family it's built on is the right tool.