NVIDIA just open-sourced their latest computer vision model, LocateAnything, and it's 10x faster than Qwen3-VL. One 3B-param checkpoint, four jobs: object detection, GUI element grounding, document layout, and OCR. Open weights, open code, live Hugging Face demo.
Project page: research.nvidia.com/labs/lpr/locate-anything
The speed story
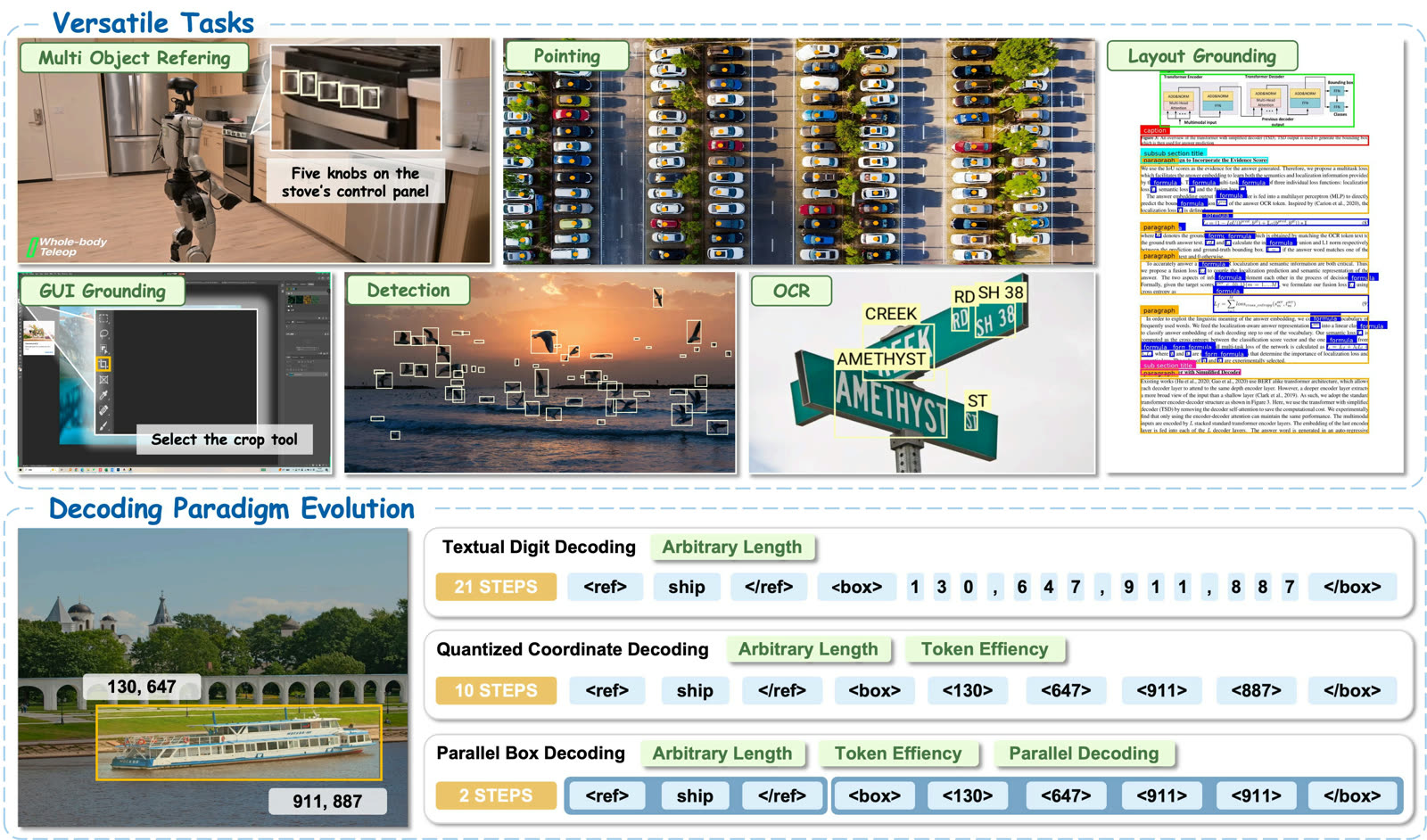
Every existing vision-language model predicts a bounding box the same way it predicts text: token by token, corner by corner. The model emits x1, then y1, then x2, then y2 as four separate decoding steps. On a dense scene with 200 boxes, that's 800 sequential predictions. The autoregressive structure also lets the model fall out of format and emit garbage tokens mid-box.
LocateAnything's trick is parallel box decoding. The model is trained to emit the full coordinate set (x1, y1, x2, y2) in a single step, treating each box as one atomic unit. That preserves the box's geometric coherence and kills 4x of the sequential decoding cost in one move. When the parallel path hits an ambiguous region, it falls back to the slow autoregressive path automatically. Hybrid by design.
The result on H100: 12.7 boxes per secondvs Qwen3-VL's 1.1 BPS. 10x. The lead widens on dense scenes (12 to 25 BPS as target boxes scale from 20 to 300), because parallel decoding is the per-box cost that compounds.
What it can actually find
One model, four task types. From the project page demos:
- Dense object detection. LVIS, COCO, Dense200, VisDrone. Beats Rex-Omni at IoU=0.95 by 10+ F1 points on LVIS.
- GUI element grounding. ScreenSpot-Pro SOTA at 60.3 F1. This is the bottleneck for every computer-use agent shipping in 2026.
- Document layout. DocLayNet 76.8, M6Doc 70.1. Tables, figures, captions, columns.
- OCR and text localisation. TotalText 43.3 F1, character-level boxes on scene text.
- Referring comprehension. HumanRef 78.7. Point at a person in a crowd by description.
The training data
LocateAnything-Data: 138 million language queries across 12 million unique images, 785 million bounding boxes. Composition is roughly:
- General object detection: 67% of queries, 83% of boxes
- GUI element grounding: 17%
- Referring comprehension: 7%
- OCR text: 4%
- Document layout: 3%
- Point-based localisation: 2%
The dataset itself is listed as "incoming" on the project page. Model weights are out now.
Where to use it
- Hugging Face model: nvidia/LocateAnything-3B
- Hugging Face demo: spaces/nvidia/LocateAnything (browser, no setup)
- GitHub: NVlabs/Eagle (Embodied)
- Paper: arxiv 2605.27365 (PDF linked on the project page)
Worth knowing
- It's a grounding specialist, not a general VLM. If you want one model that chats and grounds, you'll trade off reasoning quality. Pair it with a planner LLM.
- The 3B param size means it runs locally. H100 numbers are the headline. Consumer GPUs work too, just slower.
- Architecture: Moon-ViT vision encoder, Qwen2.5 language decoder, MLP bridge. Stitched, not from scratch.
- The decoding fallback matters. Pure parallel decoding can produce malformed boxes on ambiguous regions. Slow-mode autoregressive recovery is what makes the parallel mode shippable in practice.
Why it matters
Every computer-use agent built in the last 12 months has the same bottleneck: finding the thing on the screen. Claude Computer Use, OpenAI Operator, Browser Use, the lot. The grounding call is the slow, expensive, often wrong step. LocateAnything is the first open-weights model that beats the closed alternatives at that exact job, at 10x the speed, on a checkpoint you can run yourself. The weights being free is the real story. The 10x number is just what makes it impossible to ignore.