NVIDIA just open-sourced a speech-to-text model with only 600 million parameters. That is roughly half the size of their previous one, and it does more. It is called Nemotron 3.5 ASR, it handles 40 languages from a single model, and it transcribes in real time as you talk.
ASR stands for automatic speech recognition. It is the tech behind live captions, voice typing, and call transcription. The interesting part here is not that NVIDIA shipped another one. It is that the small version beats the bigger one on the metric that decides how much it costs to run.
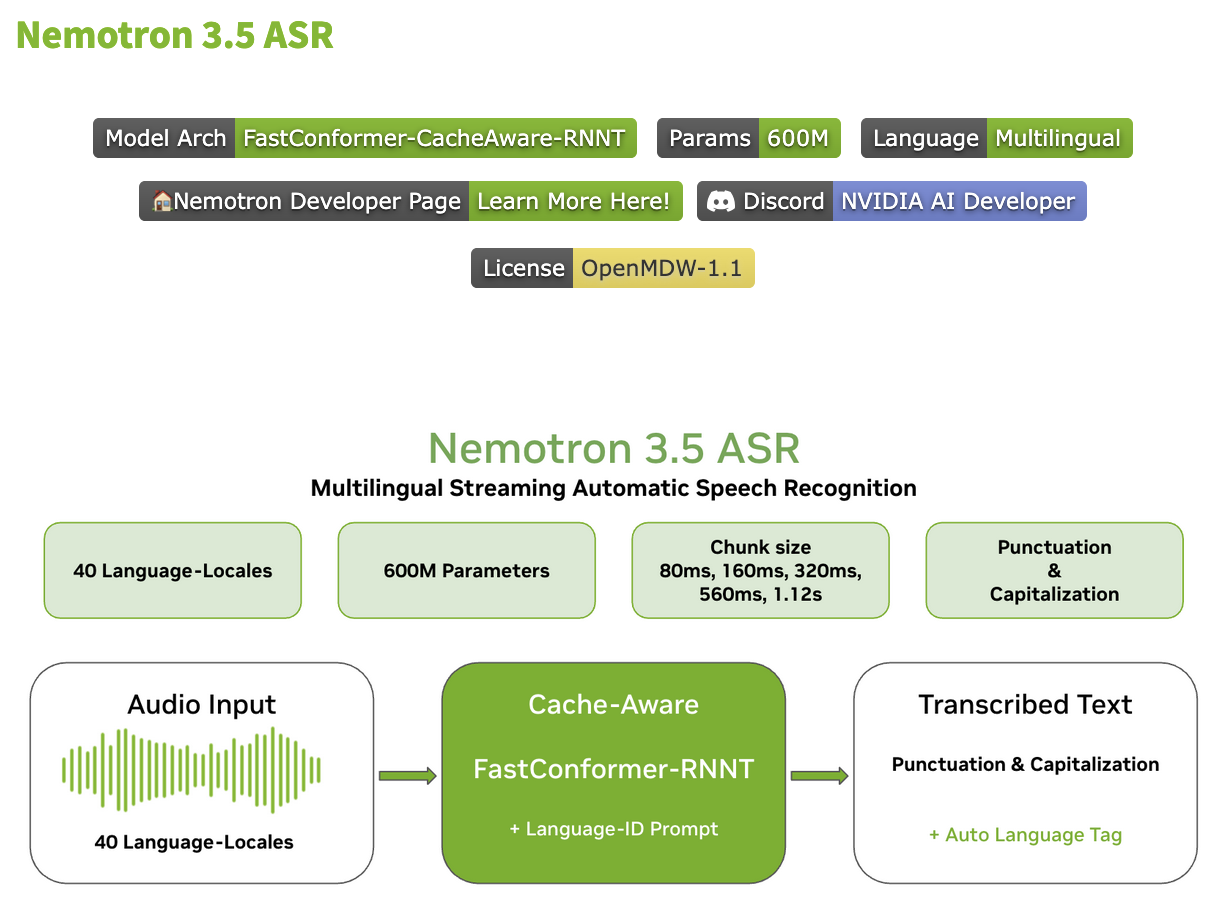
How it works: cache-aware streaming
Older streaming models transcribe by sliding a window over your audio and re-processing the overlap every step. The same chunk of speech gets read again and again. That redundant work is wasted compute, and it caps how many live conversations one chip can handle at once.
Nemotron uses cache-aware streaming instead. It breaks your speech into small, non-overlapping chunks, processes each one a single time, and keeps a cache of the context that came before. No re-reading the whole sentence. Less wasted compute per stream means far more streams per chip.
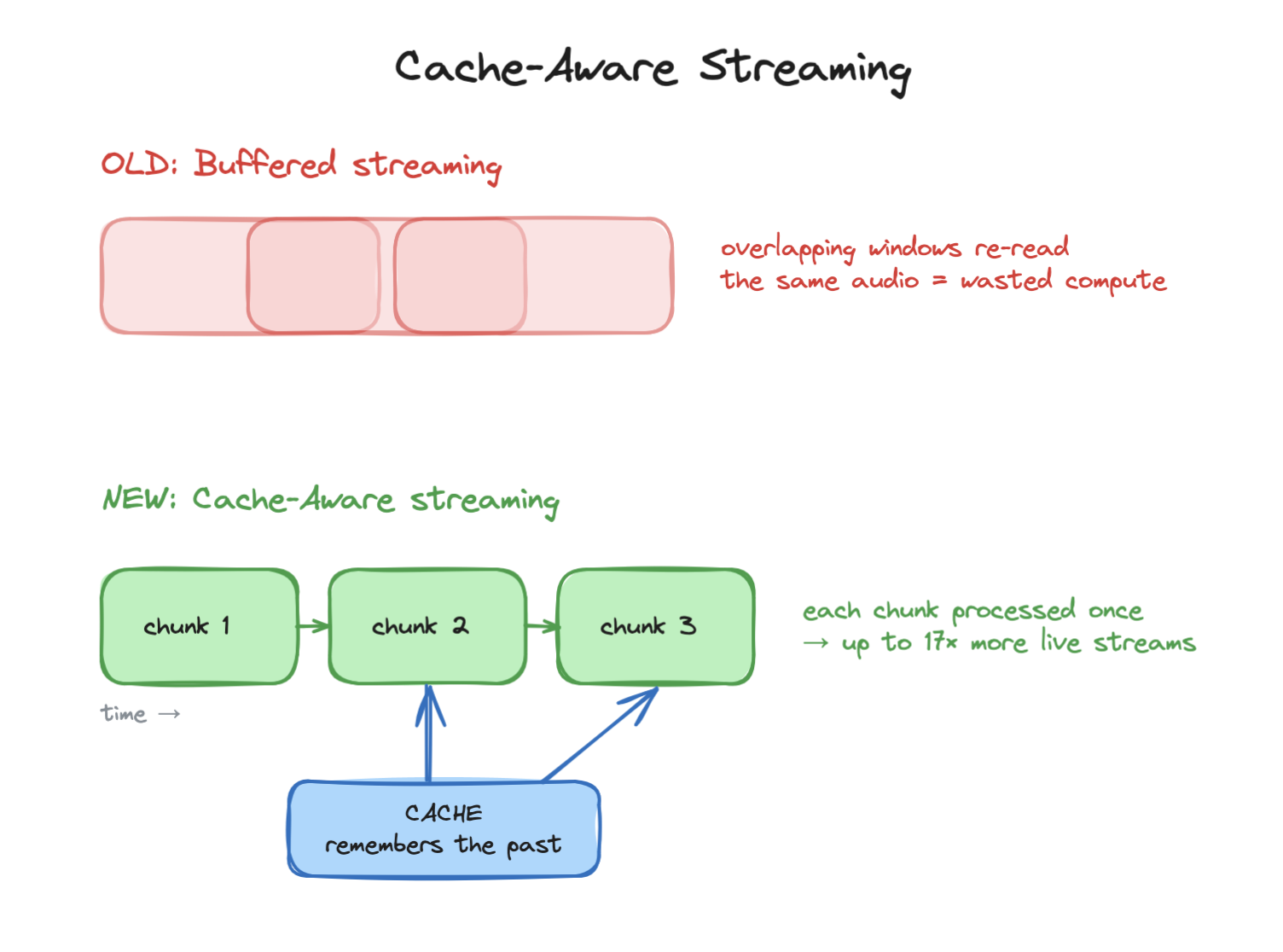
It also picks its own latency. You set the chunk size, from 80 milliseconds (fastest, for live captioning) up to 1.12 seconds (most accurate, for batch work), without retraining the model.
Why the size matters: throughput
This is the whole story. On a single NVIDIA H100, Nemotron 3.5 ASR sustains up to 17x more concurrent transcription streams than the older 1.1B Parakeet model. At the lowest-latency 80ms setting that is 240 live streams at once versus 14. At the higher-accuracy 1.12s setting it is 2,400 versus 400, still 6x more.
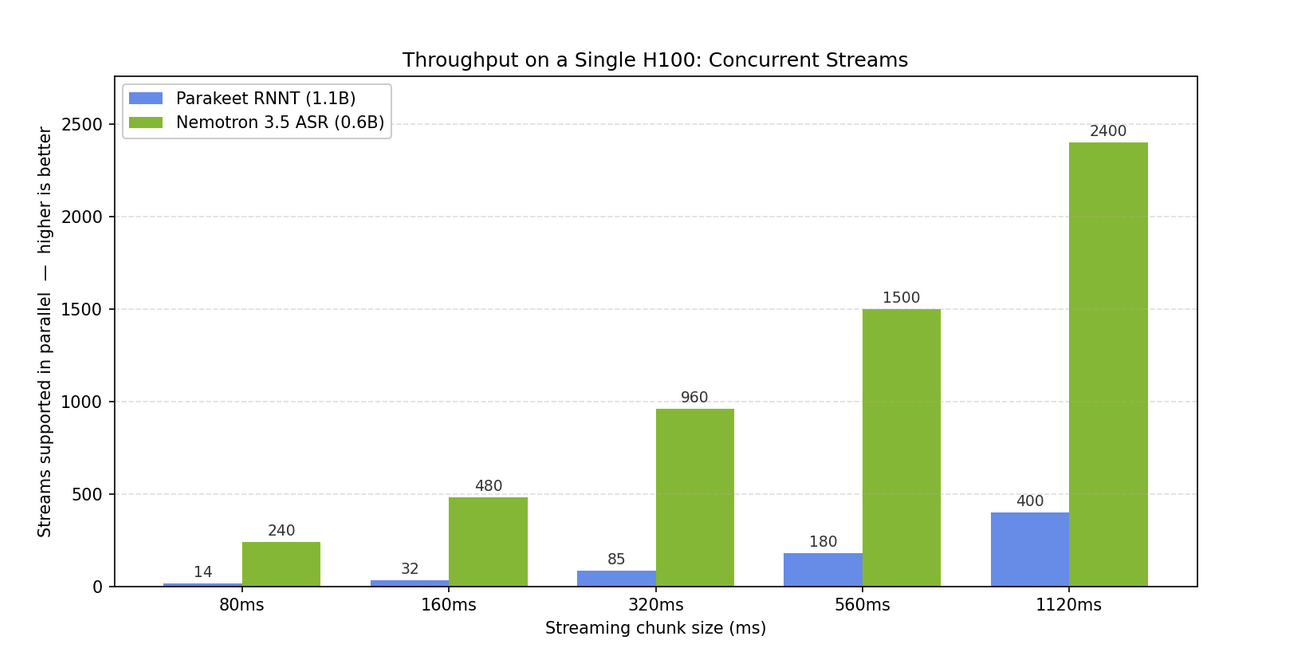
More streams per GPU means a lower cost per stream in production. That is the practical win of a smaller model: not just that it fits on less hardware, but that the same hardware does many times more work.
Accuracy holds up too. Word error rate sits around 4% on Spanish, 4.3% on Italian, and just under 8% on English, averaging roughly 8.8% across its strongest languages (lower is better). Output comes punctuated and capitalized, with optional automatic language detection. It was trained on more than 10,000 hours of multilingual audio.
A use case: live multilingual captions at scale
Say you run a streaming or events platform and you want live captions for every session, in whatever language the speaker is using. With a buffered model, one H100 might caption around 14 simultaneous streams. Past that you are buying more GPUs, and the bill climbs fast as you grow.
With Nemotron at the 80ms setting, that same single H100 covers 240 live streams. Same hardware, roughly 17x the coverage, captions appearing in near real time. For anything that transcribes many people at once, a call center, a webinar tool, a live captioning service, an in-product voice feature, the throughput gap is the difference between one GPU and seventeen.
The catch
It runs on NVIDIA hardware only: a GPU (Ampere, Hopper, Blackwell, and similar) or a Jetson board for edge deployments. It uses NVIDIA's NeMo toolkit on Linux. This is not something you double-click on a MacBook, and it does not run on a phone. It is built for people putting speech recognition into a product or onto a device, not for a desktop transcription app.
If that is you, it is free and open source under the OpenMDW-1.1 license, weights and all, on Hugging Face.
Quick facts
Model: nvidia/nemotron-3.5-asr-streaming-0.6b
Size: 600M parameters (vs 1.1B Parakeet)
Languages: 40 language-locales, one model
Latency: configurable, 80ms to 1.12s chunks
Throughput: up to 17x more concurrent streams than Parakeet on one H100
Architecture: cache-aware FastConformer-RNNT with language-ID prompting
License: OpenMDW-1.1, free and open source
Runs on: NVIDIA GPUs and Jetson, via NeMo on Linux (not laptops or phones)